The Complete Rate Limiting Handbook: Prevent Abuse & Optimize Performance for Web Services


Protecting web applications from abuse while ensuring good performance for legitimate users is a balancing act many of us face daily. Rate limiting is one of the most useful tools for achieving this balance. Let's explore how rate limiting systems work under the hood, what components you'll need, and some practical implementation approaches that stay relevant in 2025.
What is Rate Limiting?
Simply put, rate limiting controls how many requests a user, IP address, or application can make to your API or service within a specific time period. It's a traffic management technique that helps prevent abuse, reduces server load, and keeps your services running smoothly even during unexpected traffic spikes.
When properly implemented, rate limiting serves as both a security measure and a performance optimization tool. It helps protect against various threats and issues. Denial of Service (DoS) attempts can be mitigated by capping the request rate from any single source. Brute force login attacks become much harder when you limit authentication attempts. Excessive web scraping that might drain your resources is prevented. API hammering, whether intentional or accidental, won't bring down your services. And perhaps most importantly, rate limiting helps avoid resource exhaustion that could affect all your users during traffic spikes.
The Core Components of a Rate Limiting System
An effective rate limiting system consists of several interconnected components:
1. Request Identification Mechanism
Before you can limit requests, you need a reliable way to identify their source. The simplest approach is using the IP address, though this gets complicated with users behind shared IPs like corporate networks or mobile carriers. For authenticated services, API keys or tokens provide more precise control and fairness. User IDs work well for limiting based on authenticated accounts regardless of their access point. For more sophisticated needs, you might combine multiple factors such as IP address, User-Agent, and request path to create a more accurate fingerprint. Your choice of identifier significantly affects how fair and effective your rate limits will be, so consider your users' access patterns carefully.
2. Counter Storage System
Rate limiters need to track request counts across time windows. This requires a storage solution with specific capabilities. First, it needs fast read/write operations since every request requires counter verification. Second, it needs time-based expiration so counters reset automatically after their time window. Third, it needs distribution support for systems running across multiple servers or regions.
Several storage options can meet these requirements. In-memory stores like Redis and Memcached offer great performance with built-in expiration features. Distributed caches help maintain consistency across multiple application instances. Database systems can be useful when you need persistence or complex rate limit rules. Redis works particularly well for rate limiting because of its atomic operations, expiration features, and solid performance even under high load.
For high-traffic systems, you should consider implementing eventual consistency rather than strong consistency in your rate limiting architecture. With an eventually consistent approach, you maintain a local counter in each server's memory and let a background service handle synchronization with your central Redis store. The key insight here is that your request handling path doesn't hit Redis at all during normal operation, completely removing this potential bottleneck.
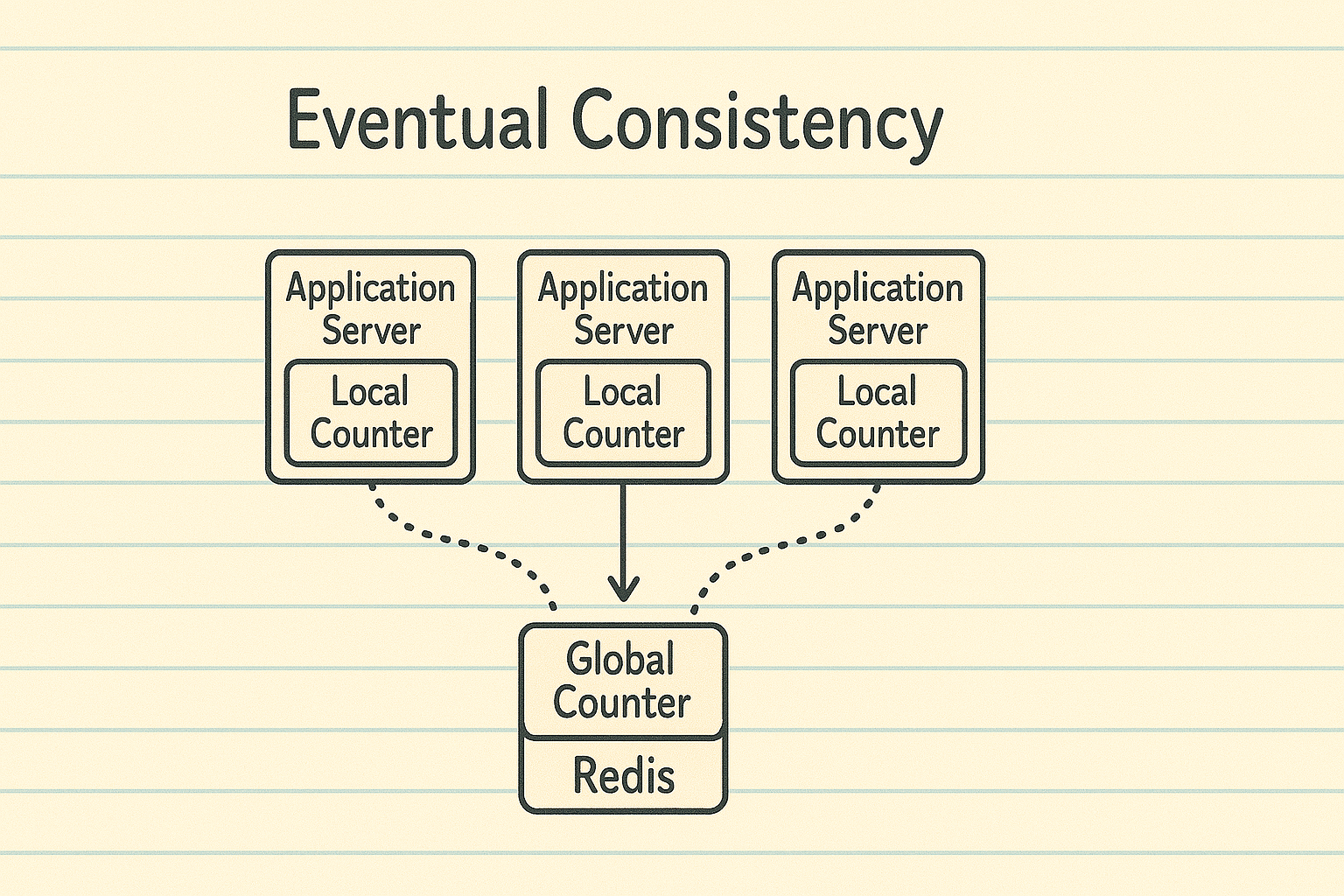
Here's how this might work in practice: Each application server maintains a local in-memory counter for active users. These local counters are incremented with each request. Separately, a background service periodically (every 5-10 seconds) reads these local counters, flushes their values to the central Redis store, and resets them. The background service also updates each server's local store with an approximation of what other servers have counted. This way, request handling only interacts with memory, never making external calls to Redis during the critical path.
This approach creates a reasonable trade-off: some users might temporarily exceed their strict rate limits by a small margin during the synchronization window, but you gain significant performance benefits by reducing database calls by orders of magnitude. For most applications, the business value of the performance improvement far outweighs the cost of occasionally allowing slightly more requests than the theoretical limit. For systems processing thousands or millions of requests per second, this approach can mean the difference between a responsive system and one that's bottlenecked by rate limiting checks.
Of course, there are situations where strict rate limiting is required—particularly for billing purposes or security-critical endpoints. In those cases, you might implement strong consistency for only those specific endpoints while using eventual consistency for the majority of your API.
3. Rate Limit Algorithms
The algorithm determines how requests are counted and limited. Each has different characteristics:
Fixed Window Counters
The simplest approach divides time into fixed windows (e.g., 1-minute intervals) and allows N requests per window.

Pros: Easy to implement and understand
Cons: Can allow traffic spikes at window boundaries (e.g., 200 requests in 2 seconds if they cross windows)
Sliding Window Counters
A more refined approach that maintains a rolling time window for each client.
Pros: Prevents boundary spikes, more accurate control
Cons: More complex to implement, requires more storage
Token Bucket Algorithm
Think of a bucket that fills with tokens at a steady rate, with each request taking a token. The bucket has a maximum capacity that allows for controlled burst capacity. Tokens are added at a constant rate (the fill rate), and requests are allowed if tokens are available. When the bucket is empty, requests are rejected until more tokens are added. This provides a good balance between consistent rate limiting and accommodating occasional traffic spikes.
Pros: Allows controlled bursts while maintaining overall rate control
Cons: Requires tuning of bucket size and fill rate
Leaky Bucket Algorithm
Similar to token bucket but focuses on processing requests at a consistent rate. Requests enter a queue (the bucket), and they're processed at a steady rate regardless of how quickly they arrive. If the bucket overflows because too many requests arrive too quickly, new requests are rejected. This ensures a very consistent outflow of processed requests.

Pros: Provides consistent request processing rate
Cons: Less flexible for handling legitimate traffic bursts
Key Difference Between Token and Leaky Bucket
The fundamental difference between these algorithms lies in how they handle traffic spikes. Token bucket focuses on limiting the average rate while allowing bursts up to the bucket size, making it ideal for APIs that can handle occasional surges. Leaky bucket, on the other hand, smooths traffic to a consistent rate regardless of input patterns, making it better suited for protecting downstream systems that require steady, predictable load. Think of token bucket as controlling the average with flexibility for peaks, while leaky bucket strictly controls the maximum processing rate at any given moment.
4. Response Mechanism
When a request exceeds the limit, your system needs to respond appropriately. The HTTP 429 status code "Too Many Requests" is the standard response that indicates rate limiting. Including a Retry-After header tells the client when they should try again, which helps manage their expectations. Custom headers like X-RateLimit-Limit, X-RateLimit-Remaining, and X-RateLimit-Reset provide information about limits and remaining quota, allowing clients to adapt their behavior. A clear response body that explains the limit and offers guidance helps developers troubleshoot and implement proper retry strategies.
Example response headers:
HTTP/1.1 429 Too Many Requests
Retry-After: 60
X-RateLimit-Limit: 100
X-RateLimit-Remaining: 0
X-RateLimit-Reset: 1620000000
5. Monitoring and Analytics System
An often overlooked but important component is monitoring and analyzing rate limiting behavior. Understanding usage patterns helps you distinguish between normal and unusual traffic, letting you set appropriate limits. Determining limit effectiveness ensures you're protecting resources without hampering legitimate users. Identifying which legitimate users are hitting limits helps you adjust tiers or communicate with heavy users. Spotting potential security threats through patterns of rejected requests can give you early warning of attack attempts.
It's crucial to recognize that most end users, especially in B2C applications, will rarely report if your application suddenly stops working for them due to rate limiting. They're more likely to simply abandon your service rather than contact support or file a detailed bug report. This silent churn makes comprehensive observability systems absolutely essential—you need to proactively identify when legitimate users are being incorrectly rate limited before it impacts your business metrics. Setting up alerts for unusual patterns of 429 responses, monitoring rate limit rejections by user segments, and tracking changes in traffic patterns following rate limit adjustments can help you catch these issues before they translate to lost users and revenue.
Good instrumentation helps you fine-tune your rate limiting to provide protection without hampering legitimate users, creating a balance that serves both your system's health and your users' needs.
Advanced Rate Limiting Techniques
As systems grow more complex and distributed, rate limiting techniques have evolved. Here are some modern approaches that address today's challenges:
Dynamic Rate Limiting
Unlike static rate limits, dynamic rate limiting adjusts thresholds based on real-time system conditions. This approach optimizes resource utilization by being more permissive during low-load periods and more restrictive during high-load periods.
Dynamic rate limiting offers several key advantages over traditional static limits. It makes better use of your system resources by allowing more traffic when capacity is available. Users experience improved service during normal operation since limits are less restrictive when the system isn't under stress. During traffic spikes or high load, protection automatically increases without manual intervention. Perhaps most importantly, your rate limiting system adapts to changing conditions in real-time, reducing the need for constant tuning and adjustment.
Here's a Ruby implementation using Redis that adjusts rate limits based on server CPU usage:
require 'redis'
require 'sys/cpu'
class DynamicRateLimiter
def initialize
@redis = Redis.new(host: 'localhost', port: 6379, db: 0)
@default_limit = 100 # default requests per minute
@period = 60 # seconds in a minute
end
def get_dynamic_limit
cpu_usage = Sys::CPU.load_avg[0] * 100 # Convert load average to percentage
if cpu_usage > 80
@default_limit / 2 # Halve the limit if CPU > 80%
elsif cpu_usage < 20
@default_limit * 2 # Double the limit if CPU < 20%
else
@default_limit
end
end
def rate_limited?(user_id)
limit = get_dynamic_limit
key = "rate_limit:#{user_id}"
# Use Redis for atomic operations
current = @redis.get(key)
if current.nil?
@redis.setex(key, @period, 1)
return false
else
if current.to_i < limit
@redis.incr(key)
return false
else
return true
end
end
end
end
# Usage example
limiter = DynamicRateLimiter.new
if limiter.rate_limited?("user123")
puts "Request denied due to rate limiting"
else
puts "Request allowed"
endWhen implementing dynamic rate limiting, consider several best practices. Choose metrics that accurately reflect your system's health—CPU usage is common, but memory consumption, queue depths, or response times might better indicate your particular system's health. Make gradual adjustments to prevent sudden shifts in allowed traffic, as abrupt changes can cause client confusion and retry storms. Implement a feedback loop with monitoring to continually refine your policies based on observed effects. Document your dynamic policies clearly in your API documentation so clients understand why limits might change over time.
Rate Limiting with API Gateways
Modern API gateways like Ambassador Edge Stack, Kong, and AWS API Gateway provide built-in rate limiting features that solve many distributed system challenges. These gateways offer centralized control, allowing you to manage rate limits from a single configuration point rather than implementing limiters in each service. They maintain consistency by using shared data stores like Redis to track request counts accurately across all instances. As your API traffic grows, these gateways scale your rate limiting alongside it, ensuring protection even as load increases.
For example, Kong offers plugins that support various algorithms and can be configured per-service or globally:
curl -X POST http://kong:8001/services/my-service/plugins \
--data "name=rate-limiting" \
--data "config.minute=100" \
--data "config.policy=redis" \
--data "config.redis_host=redis-server"In cloud-native environments, these gateways integrate well with container orchestration systems like Kubernetes, providing both flexibility and reliability. They often use centralized data stores like Redis for consistency across distributed systems, which is crucial for preventing inconsistent rate limiting decisions that could frustrate users or create security gaps.
Edge Rate Limiting
Implementing rate limiting at the edge of your network—closer to your users—offers several advantages over traditional approaches. By making rate limit decisions before requests reach your origin servers, you significantly reduce latency for legitimate users and protect backend resources. Excessive traffic is blocked at the network edge, preventing it from consuming precious backend computing resources. For applications with users around the world, edge rate limiting provides consistent enforcement across geographical regions, creating a fair experience regardless of location.
SaaS Custom Domains offers particularly powerful edge rate limiting capabilities for SaaS applications. Our service allows you to create granular rate limits based on multiple criteria including IP address, HTTP headers, cookies, domain host, path, query string, and authorization headers. This level of specificity is especially valuable for SaaS applications with different usage tiers or those needing to implement per-user rate limiting. We do not restrict advanced rate limiting features only to enterprise plans, SaaS Custom Domains makes these capabilities accessible to businesses of all sizes.
The platform allows you to configure rate limits at both the upstream/origin level (applying to all associated custom domains) and at the individual custom domain level, providing flexibility to implement general protection while maintaining granular control for specific domains. This multi-layered approach is particularly useful for protecting high-value or resource-intensive endpoints while maintaining appropriate limits for standard traffic.
Other platforms like Fastly and Cloudflare also provide edge rate limiting capabilities, though with varying levels of flexibility. Cloudflare's standard offering only allows rate limiting based on IP addresses—to create limits based on HTTP headers, cookies, and other more sophisticated criteria, you need to purchase their expensive Enterprise plan. This limitation can be significant for businesses requiring more granular control without the enterprise-level investment. Fastly can limit requests based on various criteria and apply penalties for exceeding limits, helping mitigate abuse like scraping or DDoS attacks. Cloudflare integrates rate limiting with other security features like bot management, providing comprehensive protection against various threat vectors.
When implementing edge rate limiting, be aware of some technical considerations. There may be slight precision trade-offs—Fastly notes up to 10% undercounting in high-traffic scenarios, so you might need to adjust thresholds accordingly. For very high-traffic applications, understand the capacity limitations of your edge rate limiting solution. And always balance protection and legitimate access needs when configuring rules to avoid blocking valid users.
Enhanced Monitoring and Analytics
Modern rate limiting systems benefit from comprehensive monitoring that goes beyond simple counters. Metrics collection systems like Prometheus gather detailed data on allowed and rejected requests, providing insights into patterns and trends. Visualization dashboards display request patterns over time and geographically, helping you understand usage across different regions and time periods. Detailed logging of rate limit events enables pattern analysis that can identify potential abuse before it becomes problematic. Notification systems alert you to unusual spikes or repeated violations, allowing quick response to potential attacks.
These monitoring tools help you understand your traffic patterns in multiple ways. By tracking usage patterns, you can set appropriate limits that balance protection and accessibility. Identifying normal versus peak usage behaviors helps you distinguish between legitimate traffic spikes and potential attacks. Determining if your limits effectively protect resources without impacting legitimate users ensures you're not being too restrictive or too permissive. And detecting potential attacks through sudden spikes or repeated violations gives you early warning of security issues, allowing proactive response.
Implementation Considerations
Distributed Systems Challenges
When deploying rate limiting across multiple servers or regions, you'll face several additional challenges that don't exist in single-server environments. Maintaining consistency becomes critical—counters must be accurate across all instances to prevent users from exceeding limits by distributing requests across different servers. Minimizing the performance impact of distributed counter checks requires careful design to avoid adding significant latency to each request. Handling failures gracefully becomes essential; if your rate limiting service becomes unavailable, you need predefined policies for whether to allow or deny requests during the outage.
One pragmatic approach for globally distributed applications is to implement region-specific counter storage instead of fully global counters. With this strategy, you'd maintain separate rate limiting stores for each geographic region or datacenter where your application is deployed. The request identifier would include both the client IP address and the region, ensuring that counters are scoped to specific regions.
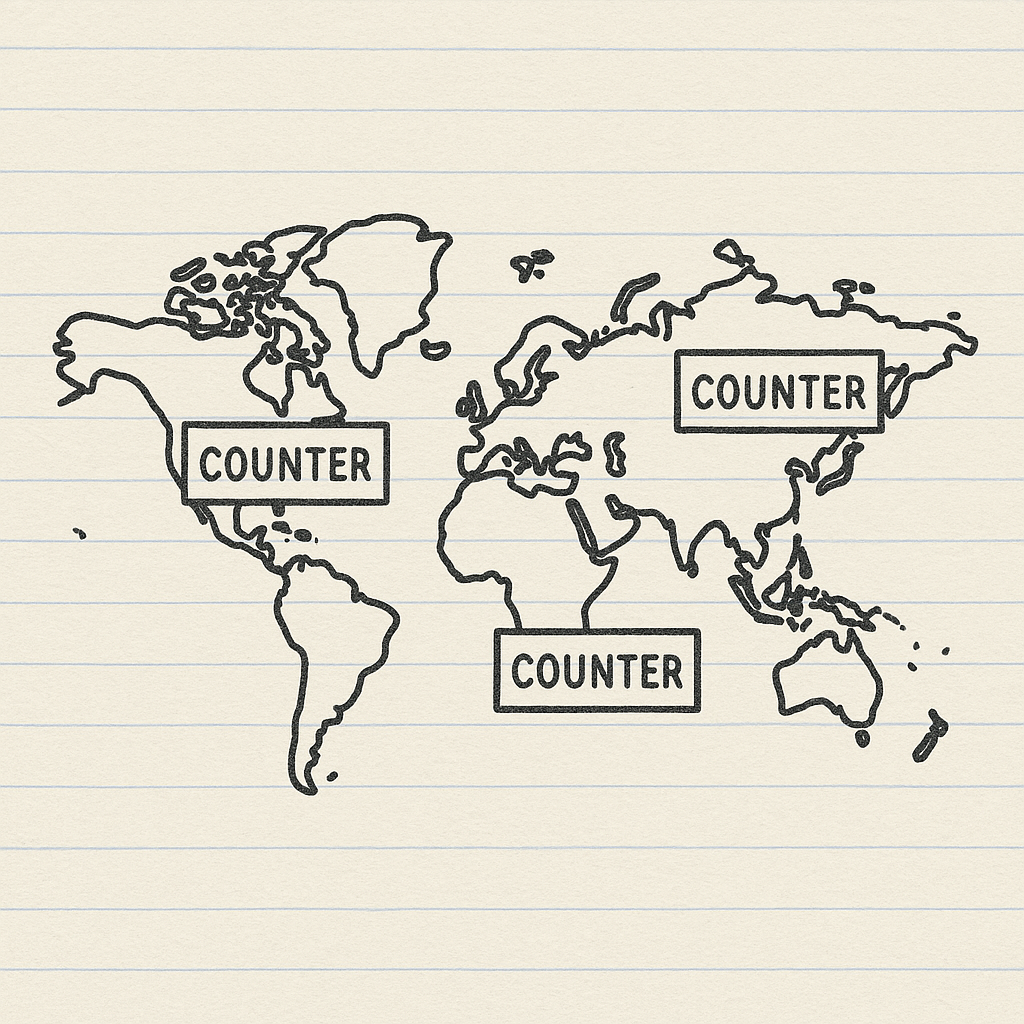
This approach works particularly well when your traffic routing typically sends requests from the same IP address to the same datacenter—which is common with modern CDN and edge routing mechanisms that direct users to the nearest point of presence. The main advantage is significantly reduced latency since rate limit checks don't need to consult a globally distributed database for every request.
There is a trade-off, however. If a determined user intentionally routes requests through different regions (using proxies or VPNs), they might exceed your intended global limit. For most applications, this risk is acceptable when balanced against the performance benefits. For high-security applications, you might implement both regional counters for performance and global counters for absolute protection.
Redis Cluster or similar distributed caching solutions can help address these issues by providing a centralized, consistent data store with high availability and performance characteristics suitable for rate limiting. For region-specific implementations, you can deploy independent Redis instances in each region while maintaining minimal cross-region synchronization for global limits when necessary.
Rate Limit Granularity
Design your limits with appropriate levels of detail to match different use cases and user types. Global limits protect overall system resources and provide a baseline defense against abuse. Service-specific limits allow different rates for different API endpoints based on their resource consumption and sensitivity. User tier limits provide varying allowances based on service level, rewarding paying customers with higher capacities. Resource-based limits assign higher limits to lightweight operations and stricter limits to resource-intensive operations.
An example tiered structure might look like this:
Free tier: 100 requests/minute
Basic tier: 1,000 requests/minute
Enterprise tier: 10,000 requests/minute
It's crucial to consider not only the threshold numbers but also the time window granularity. Very short time windows (like per-second limits) require more frequent counter updates and synchronization, increasing the likelihood of counter inconsistencies in distributed systems. They also consume more system resources to maintain. As a general rule, reserve the finest-grained time windows (e.g., 100 requests/second) for premium tiers where the additional operational complexity is justified by the revenue. For free or basic tiers, longer windows like per-minute or per-hour limits are more manageable from an infrastructure perspective while still providing adequate protection.
Adaptive Rate Limiting
More advanced systems can implement adaptive rate limiting that goes beyond simple dynamic adjustments. Automatically adjusting limits based on server load allows your system to respond to changing conditions without manual intervention. Implementing progressive penalties for abusive clients helps discourage bad behavior while still allowing legitimate users full access. Using pattern detection to identify and respond to unusual behavior can help you spot and mitigate attacks before they cause significant disruption.
Best Practices for Rate Limit Configuration
1. Make Limits Visible and Understandable
Always communicate limits clearly to your API consumers. Document rate limits in your API documentation, including specifics about different tiers, endpoints, and any dynamic adjustment policies. Return informative headers with each response so clients can track their usage and adjust accordingly. Provide a way for clients to check their current usage and limits without consuming their quota, helping them plan their request patterns more effectively.
2. Design for Graceful Degradation
Instead of completely blocking excess traffic, consider more nuanced approaches that maintain functionality even during high load. Prioritizing certain request types during high load ensures critical operations continue while less important ones are limited. Serving cached responses for read operations reduces backend load while still providing useful data to clients. Queuing less critical operations for later processing allows you to smooth out traffic spikes without rejecting requests outright.
3. Implement Proper Backoff Strategies
Guide your clients on implementing exponential backoff when receiving rate limit responses. This approach helps clients recover from rate limiting without creating additional traffic spikes. The strategy gradually increases wait time between retries, starting with a small delay and doubling it with each failed attempt. Adding a small random component helps prevent all clients from retrying simultaneously. Setting a maximum wait time prevents excessive delays for legitimate requests during temporary capacity issues.
A typical implementation follows this pattern:
1. Wait 1 + random_number_milliseconds seconds
2. If still rate limited, wait 2 + random_number_milliseconds seconds
3. If still rate limited, wait 4 + random_number_milliseconds seconds
...and so on, typically capping at a maximum wait time
4. Test Your Rate Limiting System
Regularly test your rate limiting implementation to ensure it behaves as expected under various conditions. Simulate traffic spikes to verify your system remains stable and continues to protect resources effectively. Verify that limits are properly enforced across different endpoints, user types, and access patterns. Check that legitimate traffic patterns aren't disrupted by overly aggressive rate limiting. Test distributed system scenarios, including partial outages and network partitions, to ensure resilience.
Real-World Rate Limiting Scenarios
API Protection
A public API typically requires multiple layers of rate limiting to balance accessibility and protection. Request limits per IP address prevent basic abuse by restricting unknown sources to a reasonable request rate—perhaps 10 requests per second. Service-specific limits based on API keys enforce usage tiers and help you track and bill for resource consumption, with typical limits like 1000 requests per hour. Authentication endpoints need special protection, with stricter limits like 5 failed attempts per minute to prevent credential stuffing attacks that try to guess passwords through brute force.
Login Security
Authentication systems benefit from carefully designed rate limiting. Limiting attempts per account prevents attackers from guessing passwords for known usernames, with typical limits around 5 attempts per minute per account. IP-based limits add another layer of protection by restricting the total login attempts from a single source, regardless of username, with limits like 20 attempts per hour. Progressive delays after failed attempts make brute force attacks increasingly time-consuming and impractical, with each subsequent failure requiring longer waits before retry.
Content Scraping Prevention
Content-heavy sites need strategies to prevent automatic scraping that could strain resources or steal valuable information. Session-based page view limits restrict the number of pages a user can access in a given time period, catching automated scrapers that move too quickly through content. Limiting requests for static assets by referrer helps identify and block requests that don't come from legitimate page views. Tracking unusual access patterns, such as sequential access to all pages or accessing pages in alphabetical order, can help identify and block behavior that doesn't match human browsing patterns.
Conclusion
A thoughtfully designed rate limiting system is essential for modern web applications and APIs. By understanding the core components—identification, storage, algorithms, response handling, and monitoring—you can implement effective rate controls that protect your systems while providing a good experience for legitimate users.
As we've seen, rate limiting has evolved beyond simple static rules to include dynamic approaches, edge implementation, and integration with API gateways. These advancements allow for more efficient resource utilization and better protection against emerging threats.
Rate limiting isn't just about security; it's about ensuring fair resource allocation, consistent performance, and system stability even under unexpected conditions.
At SaasCustomDomains.com, we've implemented these rate limiting principles in our custom domain management platform. If you're looking for a solution that handles these technical details for you, check out our rate limiting features and see if they fit your needs.

